|
アヴィデア社は、企業間におけるデータ交換と AI 予測モデルの実行環境として、Avgidea Data Platform(ADP)に Data Exchange と Function 機能を新たに実装しました。データエンジニアやデータサイエンティストは顧客やグループ企業とのデータ交換 / 加工処理や AI 予測モデルの展開にかかる作業負荷を軽減することができます。 ADP は、アヴィデア社が提供する SaaS の形態に加えて、企業が保有する Google Cloud™️ プロジェクトに OEM 製品として導入し、自社ユーザー向けサービスとして提供することも可能です。OEM 製品として導入後は、アヴィデア社が新機能の追加・アップデートの適用や監視・運用保守などのメンテナンス作業を実施します。 Avgidea Data Platform に新たに2つのコンポーネントが追加されました。 Avgidea Data Exchange(ADX) ADX は、異なるベンダーが提供するパブリック クラウド上の各種データサービスと連携し、ユーザーはノーコードでデータを異なるストレージやデータベースに移動することができます。また、データの保有者は、データの交換先および交換対象のデータを明示的に選択することでデータの共有範囲を限定することができます。 ソーシャルネットワーキングサービスのようにプラットフォーム上でデータが共有されたユーザー間のみでコミュニケーションがはかれるため、閉じた環境下で他のユーザーと交流が行えます。 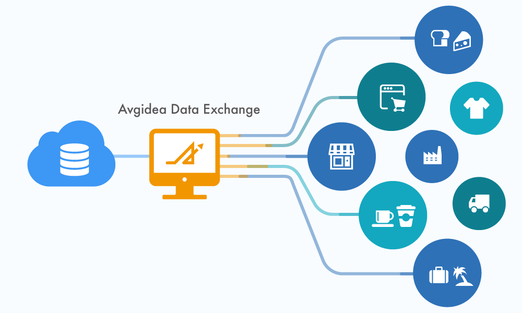 Avgidea Function(AFX) AFX を活用することにより、ADP 上のストレージに蓄積されたファイルやディレクトリに対して、データベースに取り込む前に発生するデータのクレンジング作業や文字コード変換などの前処理を Python で記述した関数として実行することができます。 また、Python のカスタム パッケージや TensorFlow™️、PyTorch™️、scikit-learn™️ などで構築された AI の予測モデルをライブラリとして添付し、ADP のストレージ上のファイルに対して処理を実行させることも可能です。AFX に登録された関数を GUI 上で明示的に共有することにより、データサイエンティストが作成した AI 予測モデルをエンドユーザーが直接実行することができます。 scikit-learn クラスタリングの実行:https://youtu.be/rkCMaDUMZj4 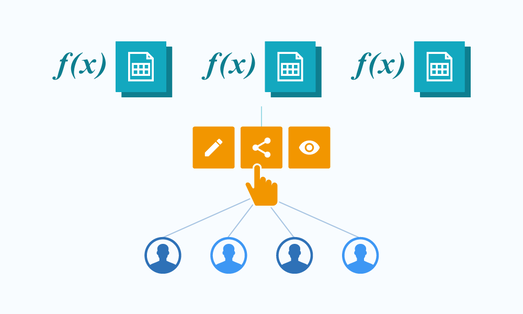 Avgidea Data Platform の利用シーン
2 Comments
オープン データは、世界中に点在する様々なサイトで提供されており、利用者は求めるデータをその都度インターネット上から探し出す必要があります。該当するデータを見つけた場合、一旦ローカル環境にファイルとしてダウンロードし、データの加工や集計を様々なツールを用いて行います。 今回リリースした ADP のコンポーネント「Avgidea Data Search」と「Avgidea Query Editor」は、表計算サービスとして利便性の高い Google スプレッドシートにデータの検索とクエリー機能を実装することにより、利用者が最小限の作業でオープン データを取り扱える環境を実現しました。 ADP はすでに海外向けに提供されており、リリース後 12 万以上のインストール数を獲得しています。今後、更なるユーザーの利用率の向上を目指し、より利便性の高い機能の追加を計画しています。 Avgidea Data Search( ADS ) Avgidea Data Search からインターネット上に点在する様々なオープン データを検索し、シングル クリックで Google スプレッドシートに直接データを取込むことが可能です。 ADS は ckan および Dataverse API の一部をサポートしており、インターネット上に展開されているインスタンスから CSV データを容易に取込めます。ADS には、国内外の ckan と Dataverse の利用可能なエンドポイント一覧が最新の状態で登録されており、利用者はリストからエンドポイントを選択するだけで、必要なデータを検索することができます。 総務省が運用する「https://www.data.go.jp」も検索の対象としています。 Avgidea Query Editor( AQE ) Avgidea Query Editor は、SPARQL に準拠したサイトにクエリーを直接発行し、Google スプレッドシートに取得したデータを出力することができます。SPARQL に準拠しているデータ プラットフォームのエンドポイントがインターネットに公開されていれば、AQE 経由で Google スプレッドシートに SPARQL クエリーの実行結果を取込めます。 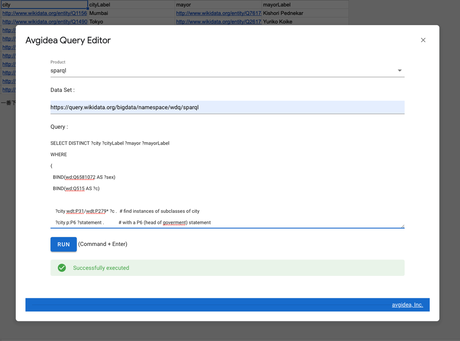 導入方法
Avgidea Data Search と Avgidea Query Editor は、Google スプレッドシートのアドオンとして提供されているため、既存の Google アカウント(G Suite™️ または Gmail™️)で G Suite Marketplace からインストールし、無料プランでの限定利用を即座に開始することができます。 インストール ガイド:https://www.avgidea.io/installation.html 制限が解除された状態でご利用されたい方は、直接アヴィデア社の Web サイトよりサブスクリプション プランをご購入いただけます。サブスクリプションの対象期間中は、機能追加や自動アップグレードを受けることができます。 Google Cloud Platform を用いた並列計算処理を実現https://prtimes.jp/main/html/rd/p/000000001.000056702.html 株式会社アヴィデア(代表取締役:八木橋徹平、以下アヴィデア)は、博報堂社内の戦略ブティック Paasons Advisory(パーソンズ・アドバイザリー)が手掛けるクロス集計・解析業務を高度にサポートする仕組みとして、Google Cloud™️を活用した高速クロス集計システムを新たに開発しました。2020 年 3 月より Paasons Advisory のアナリストが試験的に利用を開始しています。 アヴィデア は、IT技術を用いて様々なビジネス アイデアを具現化し、サービスやアプリケーションとしてユーザーに提供します。また、G Suite™️や Google Cloud Platform™️(GCP™️) などのクラウド技術を用いたシステムの開発・運用やコンサルティングを提供しています。 Paasons Advisory は博報堂社内に戦略業務に特化したブティックとして立ち上がりました。クラウドプラットフォームを駆使し、クライアントと戦略レイヤーで常時接続したコミュニティを形成しながら、高度でアジリティを伴ったプランニングサービスを提供しています。 Paasons Advisory は、通常業務において Google Cloud の G Suite を活用しており、利便性の高い Google スプレッドシート™️を用いたクロス集計システムの開発にもいち早く着手しましたが、データ量と分析軸の増加に伴う性能の劣化とクライアント端末への負荷の増加が顕著になり、本来アナリストが注力すべき解析業務への影響も出始め、この方法に対する限界を感じていました。 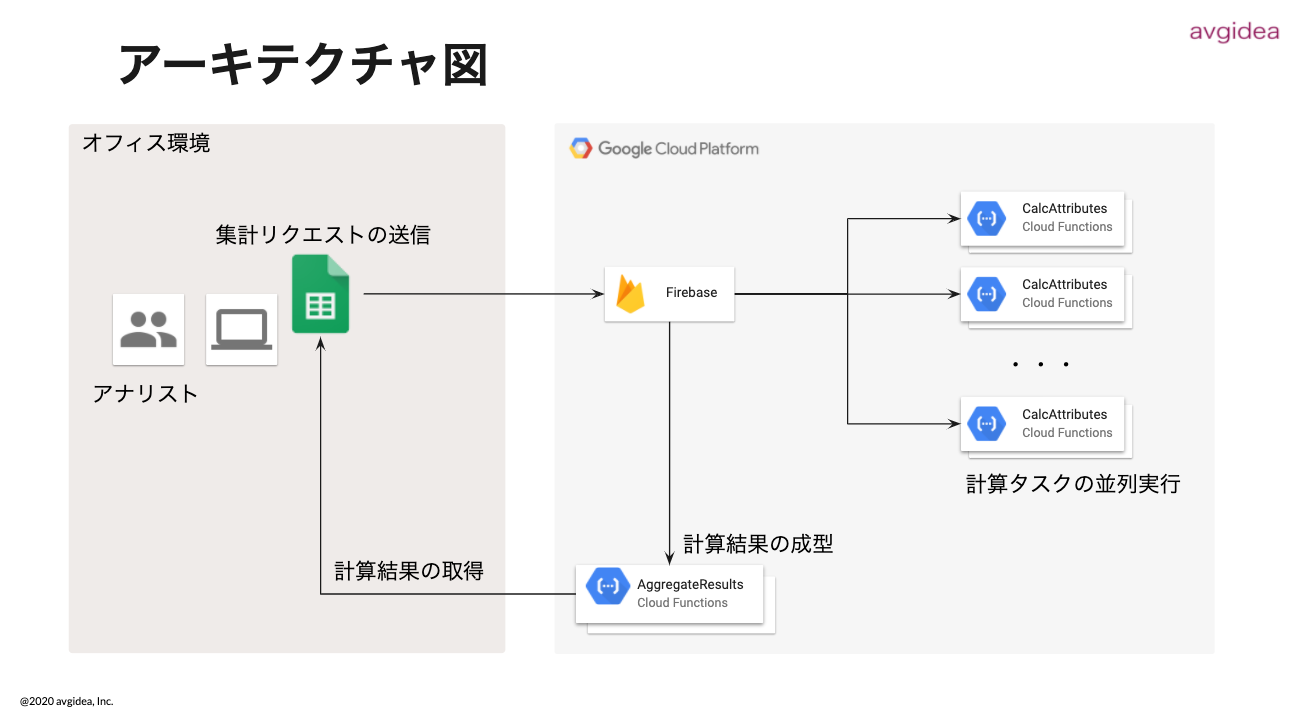 アヴィデアは、こうした Paasons Advisory の課題に対し、GCP を活用することで、高負荷な計算処理をクラウド環境で分散処理する新たな仕組みを構築しました。従来 Google スプレッドシートが担っていたデータの「保存」・「プロセス」・「描画」を分離し、保存とプロセス部分の負荷を完全に GCP へ分散し、Google スプレッドシートには描画のみさせることで、クライアント端末の負荷を大幅に下げることに成功しました。また、GCP 上での計算処理は、ハイパフォーマンスコンピューティング分野に見られるような並列実行が実現されており、計算処理時間の短縮にもつながっています。
今回、アヴィデアが Paasons Advisory 向けに実装した仕組みは、クロス集計処理を含む汎用的な並列計算基盤として活用することができるため、今後サービス化を進め他企業への有償サービスとして提供していくことを計画しています。 G Suite や Google Cloud Platform を用いたシステム開発・コンサルティングが必要な方は、ぜひ弊社にお問合せください! https://www.avgidea.io/contact.html D-Ocean のパブリックなメタデータを解析したプレプリントの論文が公開されましたdatajacket と D-Ocean に蓄積されたパブリックなメタデータを解析し、データプラットフォームの構造的な特徴を評価された研究論文です。ご興味のある方はぜひご一読ください!
タイトル Variable-Based Network Analysis of Datasets on Data Exchange Platforms https://arxiv.org/abs/2003.05109 https://arxiv.org/pdf/2003.05109.pdf 著者 東京大学大澤研究室 早矢仕晃章、大澤幸生 論文の要約 近年のデータ流通エコシステムの拡大において、組織・分野を横断したデータ共創へのニーズが高まっており、世界的にデータを交換・取引するプラットフォームが登場してきている。しかし、データ流通エコシステムは萌芽的なシステムであるため、その特徴を理解するための適切な分析単位は確立されておらず、データプラットフォームの構造的特徴についても議論が十分であるとは言い難い。そこで本研究では、データ流通エコシステムにおけるプラットフォームの特徴を理解するため、データプラットフォームサービスで扱われるデータのメタデータに含まれる変数をベースとした構造解析を提案し、D-Oceanとdatajacket.orgの2つのサービスの構造的特徴を解析した。さらに、データプラットフォームの持続可能性と社会的受容性の観点から、プラットフォームの頑健性を評価した。 |